
動画生成AIとは?仕組み・種類・2025年の最新トレンドまで【迷子にならない地図】
夜、スマホを片手に「動画 生成 AI」って検索した。
なんかいっぱい出てくる。Sora、Veo、Firefly、Runway…。
「おすすめ」って書いてある記事を開いてみても、次の瞬間にはこうなる。
で、結局どれを触ればいいの?
そもそも動画生成AIって、何をどうやって動画にしてるの?
動画編集ってだけでもハードルがあるのに、そこにAIの話まで乗ってくる。
「知らない単語が多すぎて、勉強する前に疲れる」──あれ、地味に心が折れるやつ。
でも、気づいてほしい。迷子になる原因は、あなたの理解力ではありません。
地図がない状態で森に入ってしまってるだけなんです。
だからこの記事では、いきなりツール比較はしません。
まずは「動画生成AIとは何か」「どういう仕組みで動いているか」「種類はどう分ければ迷わないか」
そして「2025年の最新トレンドは何が本質か」。
ここを、初心者でも置いていかれない言葉で整理します。
読み終わるころには、ニュースやランキングを見ても振り回されず、
「あ、これは自分に必要」「これは今は不要」って判断できるようになるはずです。
検索窓の先には、悩む誰かの指先がある。
今日はその指先に、迷子にならない地図を渡します。
- 動画 生成 AI とは?(まず「何をしている技術か」を一言で)
- 動画 生成 AI 仕組み(魔法を理解に変える)
- 初心者用:30秒でできるNanobananaProの使い方(短尺が破綻しにくくなる準備)
- うまくいかない時の「修正はここだけ」(初心者の最短デバッグ)
- 動画 生成 AI 種類(迷子の原因=分類軸がない問題)
- 動画 生成 AI メリット(時間短縮だけじゃ終わらない)
- 動画 生成 AI 最新(2025)— 何が変わった?
- 動画 生成 AI 人気/動画 生成 AI 有名 はどう決まる?(指標のズレを正す)
- 動画 生成 AI スレ/動画 生成 AI 叡智(コミュニティ情報の扱い方)
- 学び直しルート:動画 生成 AI 本/動画 生成 AI セミナー(遠回りに見えて最短の道)
- 動画 生成 AI まとめ(地図の折りたたみ)
- 動画 生成 AI 2026年トレンド予想(次に起きることを先に知る)
- FAQ:動画生成AIの初心者がつまずく質問
- 情報ソース(URL付き)+注意書き
動画 生成 AI とは?(まず「何をしている技術か」を一言で)
動画生成AIとは、ざっくり言うと「文章・画像・動画などの条件(入力)から、時間のつながりを保ちながら映像を作る技術」です。
ポイントは「1枚の絵を作る」より難しいところ。動画には時間があります。
同じ人物、同じ服、同じ背景…それをフレームを跨いで守り続ける必要があります。
動画 生成 AI が得意なこと/苦手なこと
- 得意:短尺の雰囲気づくり、企画のたたき台、広告のラフ、SNS用の最初の1本
- 苦手:長尺での整合性(同一人物・手・文字)、複雑な演技、完全に指示通りの制御
ここで覚えておいてほしいのは、動画生成AIは「完成品を一発で作る魔法」じゃなくて、
制作工程を前倒しする道具だということ。
動画 生成 AI 日本 で増えている使い方(初心者が勝ちやすい場所)
- SNS運用:ショート動画の量産より、世界観の一貫に強い
- 広告:ABテスト用のラフを早く作れる
- 採用・広報:会社の雰囲気を“映像の温度”で伝えられる
- 教育:概念説明をアニメーションで補える
迷ったらこう考えてください。
「完成を作る」より、「完成に近づく速度を上げる」ために使うと、成果に繋がりやすい。
動画 生成 AI 仕組み(魔法を理解に変える)
仕組みを理解すると、プロンプトは願い事じゃなくなる。
設計図になる。
動画 生成 AI 仕組み をざっくり図解(言葉の地図)
初心者は、まずこの4工程だけ覚えればOK。
- 条件を入れる:テキスト(文章)/画像/動画など
- 生成する:フレーム(コマ)を作る
- 整合させる:時間のつながり(人物・背景・動き)を守る
- 仕上げる:編集(カット、音、字幕、色)で“作品”にする
ここで一番難しいのが3番目。
だから動画生成AIは「画質」より前に、「一貫性」で差がつきます。

動画 生成 AI モデル の代表:拡散モデルって何?
拡散モデルは、たとえるなら霧の中から少しずつ像を浮かび上がらせる感じ。
最初はノイズ(霧)しかない状態から、段階的に“それっぽい映像”へ近づけていく。
OpenAIの技術説明では、Soraはspacetime(時空間)パッチをトークンのように扱い、
可変の解像度・長さ・アスペクト比で学習できる表現を採用していると説明されています。
超重要:この「パッチで扱う」発想により、画像も“1フレームの動画”として扱える。
つまり、画像と動画を同じ土俵で学習・生成できる設計思想があるのです。
参考(公式):OpenAI:Video generation models as world simulators
なぜ破綻する?(同一人物・手・文字・背景が崩れる理由)
破綻の大半は、「各フレームは良いのに、時間でつながらない」問題です。
- 人物の顔が微妙に変わる(別人化)
- 手指や小物が増減する(整合の崩れ)
- 文字が読めない(細部の安定性)
だから初心者が最初にやるべきは、長い動画に挑戦することじゃなくて、
短い動画で「一貫性のコツ」を掴むことです。
そして、ここで頼れるのが最新のNanobananaPro。
NanobananaProはGoogleが提供する画像生成・画像編集モデルで、Geminiの「画像を作成」から利用できます。

初心者用:30秒でできるNanobananaProの使い方(短尺が破綻しにくくなる準備)
動画生成AIでいきなり長尺を狙うと、顔・手・小物・文字が雪だるま式に崩れます。
だから先に、ブレない基準画像(参照画像)と絵コンテ(キー画像)を作っておく。これだけで破綻の修正が一気に楽になります。
1)まずは「参照画像」を3枚つくる(15秒)
NanobananaPro(Geminiの画像生成)で、同じ人物を次の3パターンで作ります。
- 正面バストアップ
- 横顔(右向き or 左向き)
- 全身(立ち姿)
目的はシンプル。動画生成で顔が別人化したときに、「正解の顔」を戻すための基準を用意します。
プロンプト例(そのまま使ってOK)
- 正面
「同一人物の参照画像。20代の日本人女性、黒髪ボブ、白シャツ、自然光、背景は無地、正面バストアップ、写実的、肌の質感は自然、過度な加工なし」 - 横顔
「同一人物の参照画像。上と同じ人物設定で、右向きの横顔、自然光、背景は無地、写実的」 - 全身
「同一人物の参照画像。上と同じ人物設定で、全身、立ち姿、自然光、背景は無地、写実的」
ポイント:「同一人物の参照画像」「背景は無地」「自然光」など、ブレる要素を減らす指定を先に入れておくと安定します。
2)次に「キー画像(絵コンテ)」を2〜3枚つくる(10秒)
短尺動画(3〜5秒)なら、キー画像は2〜3枚で足ります。
- 開始:どこで何が起きる?
- 中盤:動きのピークは?
- 終わり:どんな余韻?(止めの絵)
プロンプト例
「上の参照人物が、カフェでコーヒーを受け取り、軽く微笑む。映画のワンシーンのように。開始→中盤→終わりの3枚のキー画像を作る。カメラは固定、背景は同じ、色味は暖色寄り」
目的は「時間の流れ」を渡す前に、シーンの正解を静止画で固めることです。
![]()


3)動画生成AIに渡す(5秒)
ここまでできたら、動画生成AI側のプロンプトが急に楽になります。
なぜなら、もう「ゼロから想像で説明」じゃなく、基準画像を見せながら指示できるから。
動画用プロンプト例(短尺向け)
「参照画像の人物を維持。カメラ固定。3秒。カフェでカップを受け取り、目線がカメラに向いて微笑む。背景は変えない。手指の形を崩さない。自然な動き。映画風の柔らかい光。」
うまくいかない時の「修正はここだけ」(初心者の最短デバッグ)
破綻したら、全部を直そうとしないで、原因を一個ずつ潰します。
- 顔が別人化 → 「参照画像の人物を厳密に維持」「髪型・年齢・特徴を固定」
- 手が崩れる → 「手はカップを持つだけ」「複雑な指の動作を避ける」
- 背景が揺れる → 「カメラ固定」「背景は同じ」「ズームなし」
- 文字が崩れる → 文字は動画生成で無理に作らず、編集で後入れ(ここ超重要)
ミニ結論:NanobananaProで先に「参照画像」と「キー画像」を作ると、動画生成AIの破綻が起きても「何を直せばいいか」が見えるようになります。
いきなり長尺じゃない。まずは3秒でいい。整合の感覚を掴むところから始めましょう。
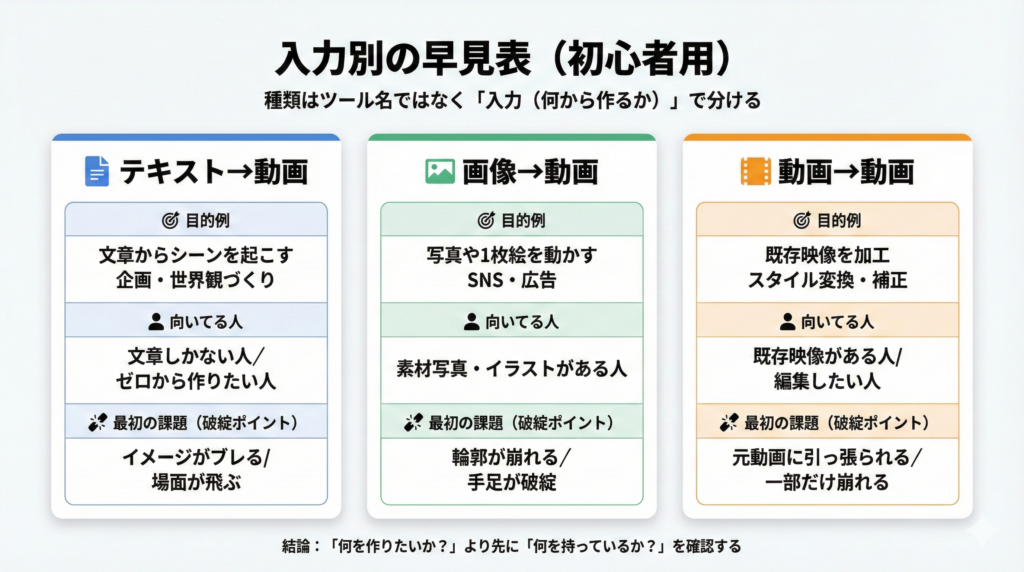
動画 生成 AI 種類(迷子の原因=分類軸がない問題)
迷子になる人の共通点はひとつ。
「種類」をツール名で覚えようとすること。
種類は、ツール名じゃなく入力(何から作るか)で分ける。これが最短です。
入力で分ける:テキスト→動画/画像→動画/動画→動画
- テキスト→動画:文章からシーンを起こす(企画・世界観に強い)
- 画像→動画:1枚絵や写真を動かす(広告・SNSで勝ちやすい)
- 動画→動画:既存映像を加工する(スタイル変換・補正・編集)
選び方の結論:
「何を作りたいか?」より先に、「何を持っているか?」を確認して。
文章しかない→テキスト→動画。素材写真がある→画像→動画。既存映像がある→動画→動画。
動画 生成 AI 日本 語 と 動画 生成 AI 英語、どっちが有利?
最初は日本語でOKです。
ただ、ツールや解説は英語が先行しやすいので、伸びる人は必要な時だけ英語に逃げるのが強い。
おすすめはこれ。
- 日本語で構図・目的・雰囲気を固める
- 英語は「カメラ」「ライティング」「質感」など短いパーツだけ使う
動画 生成 AI 中国 の動きが無視できない理由(流行じゃなく供給)
ここは煽らないで言うね。
市場として供給が増えるほど、選択肢が増え、情報が増え、初心者は迷います。
だからこそ、この記事で作った地図(仕組み・種類)を持っておくと強い。
ツールが増えるほど、判断軸を持つ人が勝つ。
動画 生成 AI メリット(時間短縮だけじゃ終わらない)
メリットは「早い」だけじゃない。
本当のメリットは、制作が前倒しになること。
企画・絵コンテ・ラフ制作が前倒しできる
- 絵コンテがなくても「雰囲気」が出せる
- 提案が速くなる(見せながら話せる)
- 修正が“文章”でできる場面が増える
動画 生成 AI 活用 事例(初心者でも再現しやすい型)
- 15秒広告:商品×使用シーン×テロップでAB案を出す
- 採用・広報:オフィスの空気感(過剰な演技は避ける)
- 教育:概念説明を短いアニメで補助
- EC:使う前→使った後のイメージを短尺で提示
小さく勝つコツ:
最初の目標は「バズ」じゃなく、1本を出せる自分を作ること。

動画 生成 AI 最新(2025)— 何が変わった?
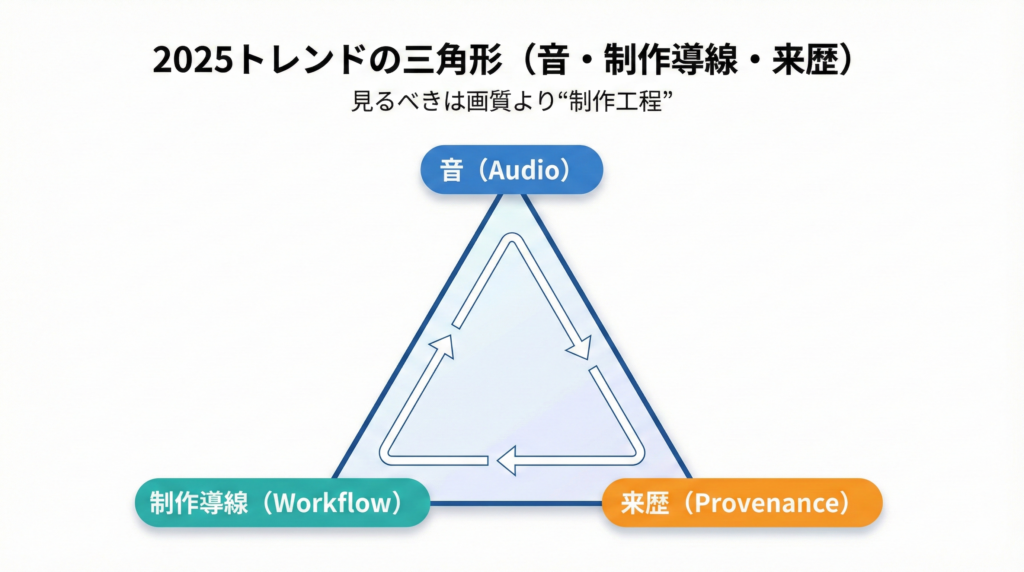
2025年の最新を追うとき、見るべきは画質より制作工程です。
「何ができるようになった?」より、「誰の仕事が楽になる?」でニュースを見ると迷いません。
2025は「映像+音」方向が強くなる(Veo 3.1の流れ)
Google DeepMindのVeo 3.1ページは、はっきり「Video, meet audio.」と掲げています。
映像だけではなく、音声を含めた表現へ軸足が移っているのが読み取れます。
参考(公式):Google DeepMind:Veo 3.1
制作フローに入る生成AI(Firefly Video Modelの狙い)
AdobeはFirefly Video Modelについて、日本語記事でも「IPフレンドリー」「安全に商用利用が可能」というメッセージを前面に出しています。
これはつまり、生成の“面白さ”より、制作現場で使える安心を取りに来ている。
参考(公式・日本語):Adobe:Firefly Video Model(日本語)
生成が進むほど、真贋(来歴)もセットで重要になる(SynthID検証)
生成がリアルになるほど、「これ本物?」が日常になる。
GoogleはGeminiアプリで、Google AIで生成/編集された動画かどうかをSynthID透かしで検証する機能を案内しています(サイズ最大100MB、長さ90秒などの制限も明記)。
参考(公式):Google:GeminiでAI生成動画を検証
参考(ヘルプ・日本語):Geminiヘルプ:SynthID Verification
初心者向けニュースの見方テンプレ
①新機能は何?(音/編集/制御/速度)
②制作工程のどこが楽になる?(企画/撮影/編集/納品)
③自分の用途に関係ある?(SNS/広告/教育/EC)
動画 生成 AI 人気/動画 生成 AI 有名 はどう決まる?(指標のズレを正す)
人気=正解、ではない。
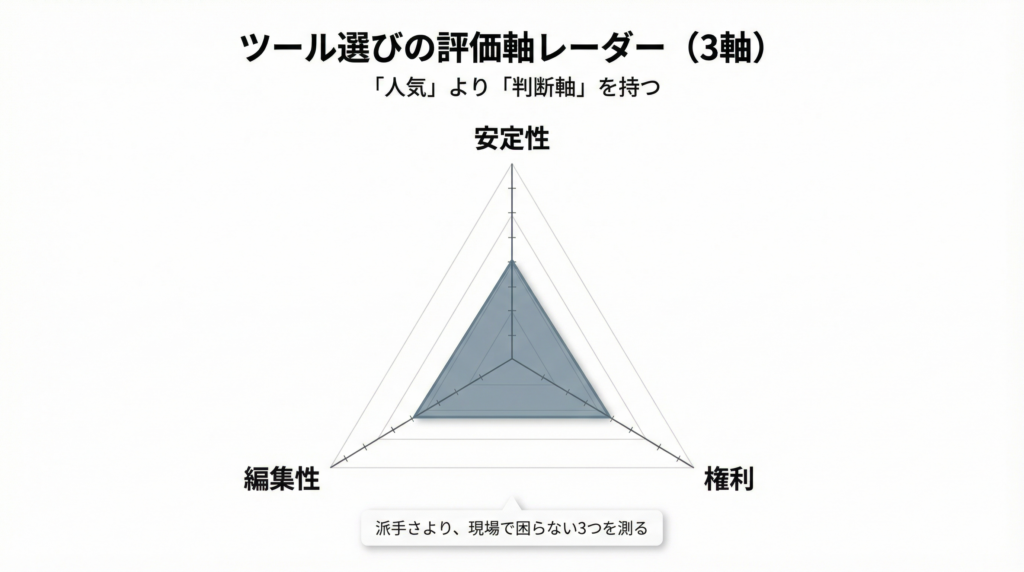
SNSでバズるツールと、制作現場で使われるツールは評価軸が違います。
初心者が見るべきは「出力」より「安定性・編集・権利」
- 安定性:同じ人物が維持できるか
- 編集性:直したい箇所を直せるか(差分修正)
- 権利:商用や公開で困らないか
ここで刺さる一言を置くね。
「人気」に乗ると速い。でも「判断軸」を持つと強い。
動画 生成 AI スレ/動画 生成 AI 叡智(コミュニティ情報の扱い方)
スレ情報は役に立つ。体験談が落ちてるから。
でも、結論だけ拾うと危ない。再現できないことが多い。
体験談は宝、結論は毒(判断基準の3チェック)
- 公式が言ってる?
- 検証動画がある?(できれば手順つき)
- 同じ条件で再現できる?
この3つを通せば、情報のノイズに飲まれにくくなる。
そして、危ない方向(規約違反や倫理的にアウト)に寄っていく話は、距離を置きましょう。
学び直しルート:動画 生成 AI 本/動画 生成 AI セミナー(遠回りに見えて最短の道)
初心者の学び方は、向き不向きがはっきり出ます。
本が向いてる人/セミナーが向いてる人
- 本:自分のペースで理解したい/体系で整理したい
- セミナー:最短で“作れる状態”に入りたい/質問しながら進めたい
初心者が最初に作る「小さな成功体験」の設計
いきなり1分を狙わない。最初はこれでいいのです。
- 3秒:雰囲気を出す(破綻してもOK)
- 5秒:同一人物を維持する
- 8〜15秒:起承転結を入れる(SNSの最小単位)
ここで一次情報の話。
「どれが良い?」の答えを外から探すより、あなたの用途でデータを取るのが早い。
一次情報テンプレ(あなたが今日取れるミニ調査)
- テスト条件:同じプロンプト(または同じ画像)で3ツールを試す
- 評価項目:①同一人物維持 ②破綻の少なさ ③手直しのしやすさ ④出力までの速さ
- 結果の残し方:生成物URL/スクショ/設定値をスプレッドシートに保存
- 結論:あなたの用途に最適な“種類”と“ツール傾向”が見える
このミニ調査は派手じゃない。だけど、一生迷いにくくなる。
検索より先に、あなたの現場で答えが出るから。
動画 生成 AI まとめ(地図の折りたたみ)
最後に、今日の地図を折りたたみましょう。
- 仕組み:魔法じゃない。工程だ。一貫性(時間)が難所。
- 種類:ツール名じゃなく、入力(テキスト/画像/動画)で分けると迷わない。
- 2025:“制作導線”“音”“権利/来歴”が本質になってきた。
最新に振り回されないコツは、最新を追わないことじゃない。
最新を理解する土台(地図)を持つことです。
動画 生成 AI 2026年トレンド予想(次に起きることを先に知る)
ここからは予想です。断定はしません。
ただ、2025時点の公式発表の“方向”から見える未来はあります。
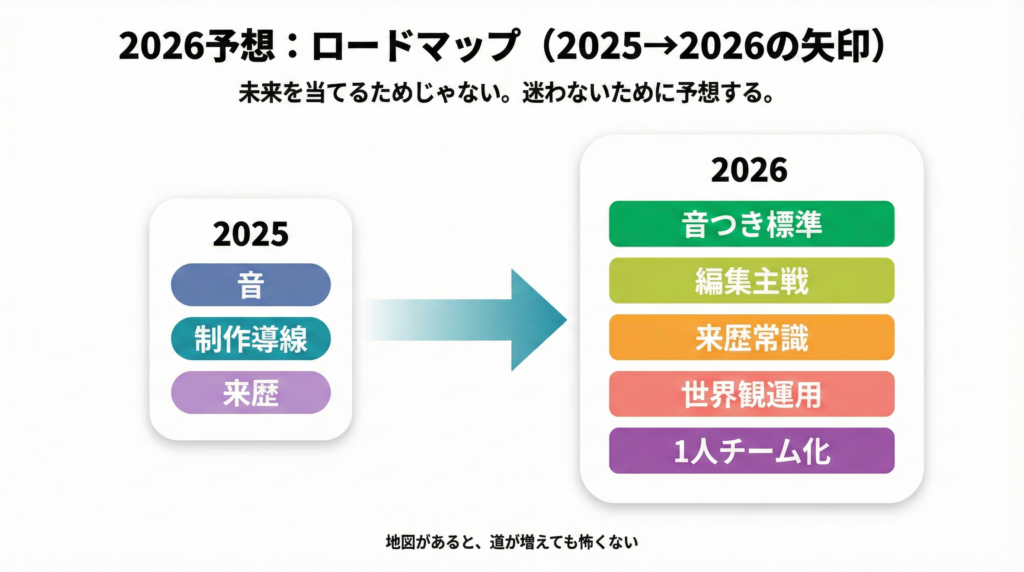
予想1:音つき生成が当たり前になる(映像+セリフ+環境音)
Veo 3.1が「Video, meet audio」を掲げている流れから、2026は動画=音込みが標準になっていく可能性が高い。
参考:Veo 3.1公式
予想2:生成より編集(修正)が主戦場になる
作るより、直す方がコストがかかる。
だから2026は、プロンプトで“差分修正”できる編集体験が主戦場になる。
予想3:来歴(生成証明)と検出が常識になる
GeminiでSynthID検証が案内されている通り、来歴確認のUIは広がっていく。
参考:Google公式
予想4:短尺量産から世界観運用へ
供給が増えるほど、短尺の「それっぽさ」はコモディティ化する。
最後に残るのは、キャラ・世界観・シリーズの一貫性。
予想5:制作の1人チーム化が進む
脚本→絵コンテ→映像→音→字幕→サムネ。
工程が分解され、統合され、1人で回せる範囲が広がる。
つまり、2026は「作れる人」より「回せる人」が強い。
最後に一言。
未来を当てるためじゃない。迷わないために予想する。
地図を持っていれば、道が増えても怖くない。
FAQ:動画生成AIの初心者がつまずく質問
動画生成AIとは何ですか?初心者でも使えますか?
動画生成AIは、テキストや画像などの条件から、時間のつながりを保って動画を生成する技術です。初心者は短尺(3〜15秒)から始め、種類(テキスト→動画/画像→動画/動画→動画)を先に整理すると迷いません。
動画生成AIの仕組みは拡散モデルって本当?
多くの生成モデルは、ノイズから段階的に像を立ち上げる拡散モデル系のアプローチが知られています。Soraの技術説明でも、時空間パッチなどの表現が紹介されています(公式リンクは記事中に掲載)。
動画生成AIの種類はどう選べばいい?(テキスト/画像/動画)
迷わない選び方は“入力”で分けることです。文章しかないならテキスト→動画、写真を動かしたいなら画像→動画、既存映像を加工したいなら動画→動画が基本です。
日本語と英語、どっちでプロンプトを書くべき?
最初は日本語でOKです。必要になったら、カメラ・光・質感など短い英語パーツを混ぜる形が失敗しにくいです。
スレの情報は信じていい?
体験談は参考になりますが、結論だけ拾うと危険です。「公式が言っているか」「検証があるか」「再現できるか」の3チェックでふるいにかけましょう。
情報ソース(URL付き)+注意書き
本記事は、動画生成AIに関する一般的な情報提供を目的としており、機能・料金・利用条件は変更される可能性があります。商用利用や公開前は、必ず各サービスの公式情報・利用規約・社内ルールをご確認ください。特に生成物の権利や利用可否は、契約形態や利用状況により判断が異なる場合があります。
■参照した主な一次/公式情報:
・OpenAI:Video generation models as world simulators(Soraの技術背景)
https://openai.com/index/video-generation-models-as-world-simulators/
・Google DeepMind:Veo 3.1(Video, meet audio)
https://deepmind.google/models/veo/
・Google:Verify Google AI-generated videos in the Gemini app(SynthID検証の案内)
https://blog.google/technology/ai/verify-google-ai-videos-gemini-app/
・Geminiヘルプ(日本語):SynthID Verification の説明
https://support.google.com/gemini/answer/16722517?hl=ja
・Adobe(日本語):Firefly Video Model(IPフレンドリー/商用安全の打ち出し)
https://blog.adobe.com/jp/publish/2025/02/13/cc-meet-firefly-video-model-ai-powered-creation-with-unparalleled-creative-control


コメント
Does your website have a contact page? I’m having
problems locating it but, I’d like to send you an email.
I’ve got some ideas for your blog you might be
interested in hearing. Either way, great blog and I look forward
to seeing it expand over time.
Thank you so much for your kind message and for your interest in my blog.
My contact page is currently under construction, so I would appreciate your patience for a little while longer.
I really appreciate your support and your ideas, and I look forward to hearing from you in the future.
Thanks again, and I hope you’ll continue to enjoy my blog.